I think we can all agree that last week's UFC event was a setback for the machine uprising. Jacob and his dog went an uninspiring 50% on their picks, and still trashed PickGPT which went a miserable 25%. The one bright spot was the Elves Brenner win, and that huge underdog almost single-handedly kept PickGPT from losing all of its winnings to date. So what happened? As I said in the last article, the complexity of neural networks makes it almost impossible to tell, but we can speculate. The most obvious explanation is that the wrestling and grappling heavy nature of the card made a neural network trained on only striking and biometric data inaccurate. In addition, the relatively large number of fighters making their UFC debuts without a Contender Series matchup led to a lack of input data for PickGPT. Finally, the limited amount of data on Abus Magomedov led PickGPT to think he landed 22 significant strikes per minute. If there were a fighter that actually landed 22 significant strikes per minute over multiple three round UFC fights, I think we would all pick that fighter to win in almost any matchup. So, on a week where I bow to Jacob’s dog, let’s lift the veil a bit and discuss neural networks at a high level and the exact data that goes into PickGPT.
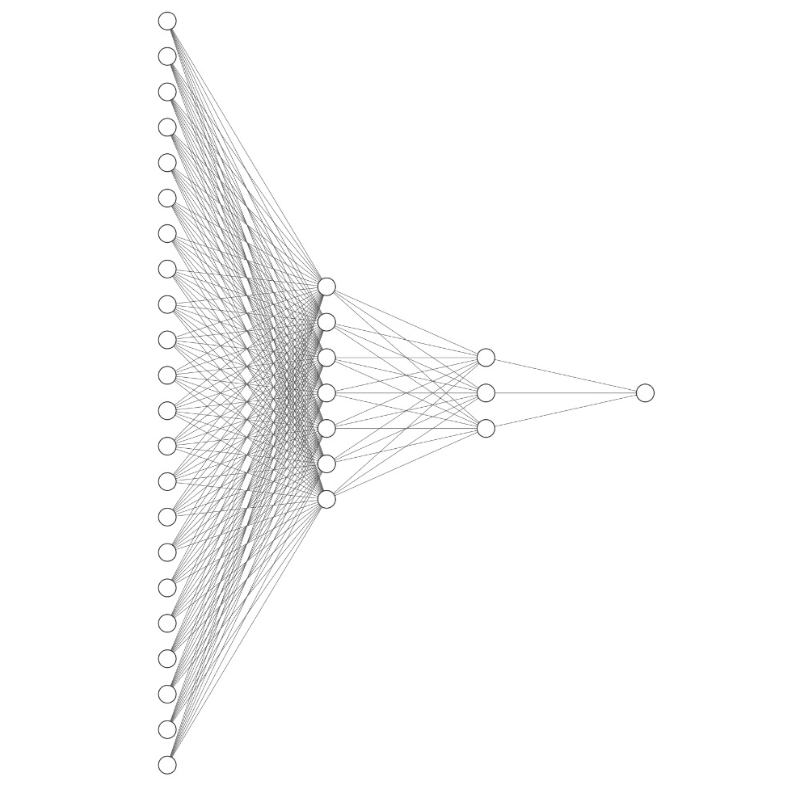
In the simplest case, a neural network is just a set of layers of nodes, connected by weights. This is supposed to mimic the connections of neurons in the brain, hence the “neural” part of a neural network. The actual current architecture of PickGPT is shown below. I only feel comfortable sharing this because it won’t remain this simple for long. Besides, you couldn’t recreate it solely based on the information in this article, even if you did have the necessary data. And why would you when you get its output for only $10 per month? To generate an output, each node takes information from each node in the layer to the left of it, combines all of that information somehow, perhaps adds a bias, and then runs it through a filter. The nodes on the left are input nodes, and can hold information about the thing you want to predict. In our case, this is information about the fighters in a fight like age, reach, strikes landed per minute, etc. The nodes on the right are the output nodes, and they are interpreted as the result we aim to predict. In this case, there is one output node, and we can encode it to be 0 if fighter 1 wins, and 1 if fighter 2 wins, with a value of 0.5 interpreted as a complete coin flip. The layers of nodes in between the input and output layers are called hidden layers.
Ok, so now that we sorta know what a neural network is, how does it work? Well, if you initialize all the weights and biases randomly, and do nothing else, it doesn’t work. It needs to LEARN. And in order to learn, it needs DATA. The data should consist of examples of things you want it to predict. A real world case is image recognition, where each input to the network is a pixel value, and the output tells you what the image is, say 0 for a picture of a cat and 1 for a picture of a dog. For this example, the model would learn by being fed many thousands of pictures of cats and dogs, while tweaking its weights and biases to increase how many it gets right. How that tweaking happens is very complicated, and requires quite a bit of advanced mathematics, however software libraries such as PyTorch, which is what PickGPT is built with, do all of this complicated math for you.
So if image recognition is the canonical problem for a neural network, in what way is fight picking similar, and not-so-similar. Well, there is some randomness in fighting that does not exist in the image recognition case. This is due simply to the nature of the sport being essentially professional face punching, and it only takes one punch to the face for a fight to end abruptly. Let’s think of an example. Consider if Alexander Volkanovski were to fight Austin Lingo this weekend. You could load both fighter's data into PickGPT, and it would likely say with high confidence that Volkanovski would win. But it’s not 100% sure in real life. Volkanovski could take a weird step and break an ankle as soon as the bell rings. In the image recognition example, the picture IS a dog or IS a cat. There is no uncertainty in the actual thing it is trying to predict. What that means for us is that, while neural nets can be practically 100% accurate at classifying images, predicting an outcome of an event with some randomness like fighting is not going to allow a neural network to achieve the same level of accuracy. But what is the cap on the level of accuracy of its not 100%? That’s a question I am actively trying to answer.
So what is stopping you, the reader, from using PyTorch to build your own version of PickGPT? Well, aside from being able to code in python, the biggest obstacle would be generating the training data set. Remember that it needs examples of the things it is trying to predict in order to learn, and neural networks in particular require a lot of examples. Image recognition neural networks typically use hundreds of thousands, or even millions of images to train, and as you probably know, there have not been hundreds of thousands of UFC fights.
Besides which, gathering data on the limited number of UFC fights that have taken place is no easy task. It would require web scraping, or an army of humans to input data from each fighter in each fight that you want to train it with. To make matters more complicated, you don’t want to give the neural network information it would not have had at the time of the fight. For instance, Alexander Volkanovski lands 6.35 significant strikes per minute ahead of this weekend's PPV. When he faced Brian Ortega, it was 6.02. If we are going to predict the outcome of a fight with the most current statistics, we should train the neural network with data that was available when that fight took place. The same thing goes for biometrics that might change, like age.
So what data am I training PickGPT with? The specific inputs that I feed into PickGPT as of right now are:
- Fight weight
- Fight gender
- Fighter 1 age
- Fighter 2 age
- Fighter 1 reach
- Fighter 2 reach
- Fighter 1 height
- Fighter 2 height
- Fighter 1 stance
- Fighter 2 stance
- Fighter 1 number of UFC fights
- Fighter 2 number of UFC fights
- Fighter 1 octagon time
- Fighter 2 octagon time
- Fighter 1 significant strikes landed per minute
- Fighter 2 significant strikes landed per minute
- Fighter 1 striking accuracy
- Fighter 2 striking accuracy
- Fighter 1 significant strikes absorbed per minute
- Fighter 2 significant strikes absorbed per minute
- Fighter 1 striking defense
- Fighter 2 striking defense
This is why there are 22 input neurons in the image of PickGPT’s architecture below. This means that in my database that I use for training, I need all of these metrics AT THE TIME EACH FIGHT TOOK PLACE. Fortunately, my database has all these stats and more, including similar stats for wrestling and grappling. So why not just load the wrestling and grappling stats right away? There are a few simple, but unsatisfying, answers to this question. First is time. Did I mention that I am a nuclear physicist? As in, I am currently working a day job as a nuclear physicist? That comes with its own set of time constraints as I am sure you can imagine. Second is curiosity. I want to see the impact on accuracy as I add (or take away) certain sets of related metrics.
Third, and most important is that I am data starved. Adding more inputs adds more weights and biases. Depending on what book or authority you read on the subject, a good neural network requires 10-30 training samples per weight and bias in the network. Right now, the database consists of the last 5,122 UFC fights that took place, stretching back to the Browne Vs Bigfoot fight card that occurred in 2012. That might sound like a lot, but if you divide that by 30 to be conservative, that is roughly 170 weights and biases at my disposal, and hence I am forced to choose which stats are meaningful and which are not. To make matters worse, some stats may be meaningful for some fights and not for others.
Finally, I hope no one lost too much money by blindly tailing last week's picks from PickGPT. At the same time, myself in last week's article, and Angelo in every YouTube appearance, did caution you that this product is in BETA and is not quite ready for prime time, but trust me, I get it. After UFC Jacksonville, I had to lean on my incredible self control not to drive to Las Vegas and bet on its picks myself. Having said that, this will probably be the last time I am quite so transparent on how the algorithm works to avoid any competition trying to recreate it. As data gets added, and statistical games are played to make the best use of the limited data available, the accuracy and complexity will increase substantially. PickGPT is under active development and improvement, and when it is ready, you will know, especially if you are reading these articles and following the journey here on We Want Picks!